Universal Parser
Note
It’s required to install reader, pdf and codes from Optional dependencies section.
The first step for using an Universal Parser, to automatically extract information from the pdf-files, is to create a new class that inherits from a UniversalParser.
The next step, in a case that the parser is not working properly or you would like it to work differently, you can implement an Extension, see UniversalParserExtension.
The extensions are then provided in the constructor of your Universal Parser, they are automatically selected then based on the context value.
At the end, you just need to implement parse_body() method, that contains overall parsing logic.
- class aiviro.modules.universal_parser.UniversalParser(extension_classes: List[Type[UniversalParserExtension]] | None = None)
Main class to inherit from for defining your parsing logic of Universal Parser.
- Parameters:
extension_classes – List of universal-parser extensions, see
UniversalParserExtension- Example:
>>> from aiviro.modules.universal_parser import UniversalParser, DocumentType >>> from dataclasses import dataclass >>> from decimal import Decimal >>> from typing import Optional >>> >>> @dataclass ... class ParserOutput: ... vat_supplier: Optional[str] = None ... invoice_date: Optional[str] = None ... total_amount: Optional[Decimal] = None ... >>> class MyParser(UniversalParser[ParserOutput]): ... def parse_body(self, pdf_r: "PDFRobot") -> ParserOutput: ... output = ParserOutput() ... output.vat_supplier = self.parse_vat_supplier_number(DocumentType.INVOICE) ... output.total_amount = self.parse_total_amount().total_amount ... # for a specific vat-number, change parsing logic to other extension-parser, ... # which is defined by a context value: "my-extension" ... if output.vat_supplier == "CZ1234567890": ... self.context = "my-extension" ... ... output.invoice_date = self.parse_invoice_date() ... return output
>>> import aiviro >>> from aiviro.modules.pdf import create_pdf_robot >>> from aiviro.modules.universal_parser import CSVWriter, QRData >>> # use defined Universal Parser in a scenario >>> if __name__ == "__main__": ... aiviro.init_logging() ... ... r = create_pdf_robot("path/to/file.pdf") ... csv_writer = CSVWriter(r) ... uni_parser = MyParser([MyExtension]) # defined in the example above ... res = uni_parser.parse( ... pdf_r=r, ... qr_data=QRData(r).extract(), ... csv_writer=csv_writer, ... ) ... print(res) ... # ParserOutput( ... # vat_supplier='CZ1234567890', ... # invoice_date=datetime.date(2020, 1, 21), ... # total_amount=Decimal('12100') ... # )
- property default_parser_extension_class: Type[UniversalParserExtension]
The default behaviour class when no context is set.
Override this method to change default behaviour
- property context: str
Currently set context for selection of a universal-parser extension.
- Getter:
Returns current context
- Setter:
Sets new context and selects appropriate parser
- parse_order_number(primary_regex: List[str] | None = None, use_predefined_formats: bool = True, primary_keywords: List[str] | None = None) List[str]
Parse order number.
- Parameters:
primary_regex – Primary format options of order-number
use_predefined_formats – If True, also predefined formats are used as possible order-number
primary_keywords – Keywords that are used at first to search for the order number.
- Example:
>>> from aiviro.modules.universal_parser.constants.keywords_regex import OrderNumberRegex >>> from aiviro.modules.universal_parser.constants.keywords_invoice import OrderNumberKeywords >>> parser = MyParser() >>> parser.parse_order_number( ... primary_regex=OrderNumberRegex.PRIMARY_REGEX_9SLASH3 + OrderNumberRegex.PRIMARY_REGEX_3SLASH9, ... primary_keywords=OrderNumberKeywords.ORDER_NUMBER_DIRECT_SUBSCRIBER_SUBSTRING, ... )
- parse_subscriber_id(doc_type: DocumentType | None = None, known_identifiers: OptionalListType = None) str | None
Parse subscriber id.
- Parameters:
doc_type – Type of document, see
DocumentTypeknown_identifiers – List of expected subscriber ids
- parse_supplier_id(doc_type: DocumentType | None = None, known_identifiers: OptionalListType = None) str | None
Parse supplier id.
- Parameters:
doc_type – Type of document, see
DocumentTypeknown_identifiers – List of ids to exclude from search
- parse_total_amount(include_amount_without_vat: bool = True) AmountValues
Parse total amount with & without vat.
- Parameters:
include_amount_without_vat – Option to also parse total amount without vat
- parse_vat_subscriber_number(doc_type: DocumentType | None = None, known_identifiers: OptionalListType = None) str | None
Parse subscriber vat number.
- Parameters:
doc_type – Type of document, see
DocumentTypeknown_identifiers – List of expected subscriber vat numbers
- parse_vat_supplier_number(doc_type: DocumentType | None = None, known_identifiers: OptionalListType = None) str | None
Parse supplier vat number.
- Parameters:
doc_type – Type of document, see
DocumentTypeknown_identifiers – List of vat numbers to exclude from search
- parse_bank_account() BankAccountValues
Parse bank account information. It parses bank account number, IBAN, SWIFT and bank name.
- parse_company_name(company_ico: str = '') str | None
Parse company name from company IČO, using ARES. Therefore, only Czech companies are supported.
- Parameters:
company_ico – Czech IČO
- parse_document_items(split_condition: BaseSplitCondition | None = None) Tuple[DocumentItemsHeader | None, List[DocItem]]
Detects and parse items in the document.
- Parameters:
split_condition – Condition to split items, see
BaseSplitCondition- Returns:
List of items containing all their text-boxes and overall area, see
DocItem
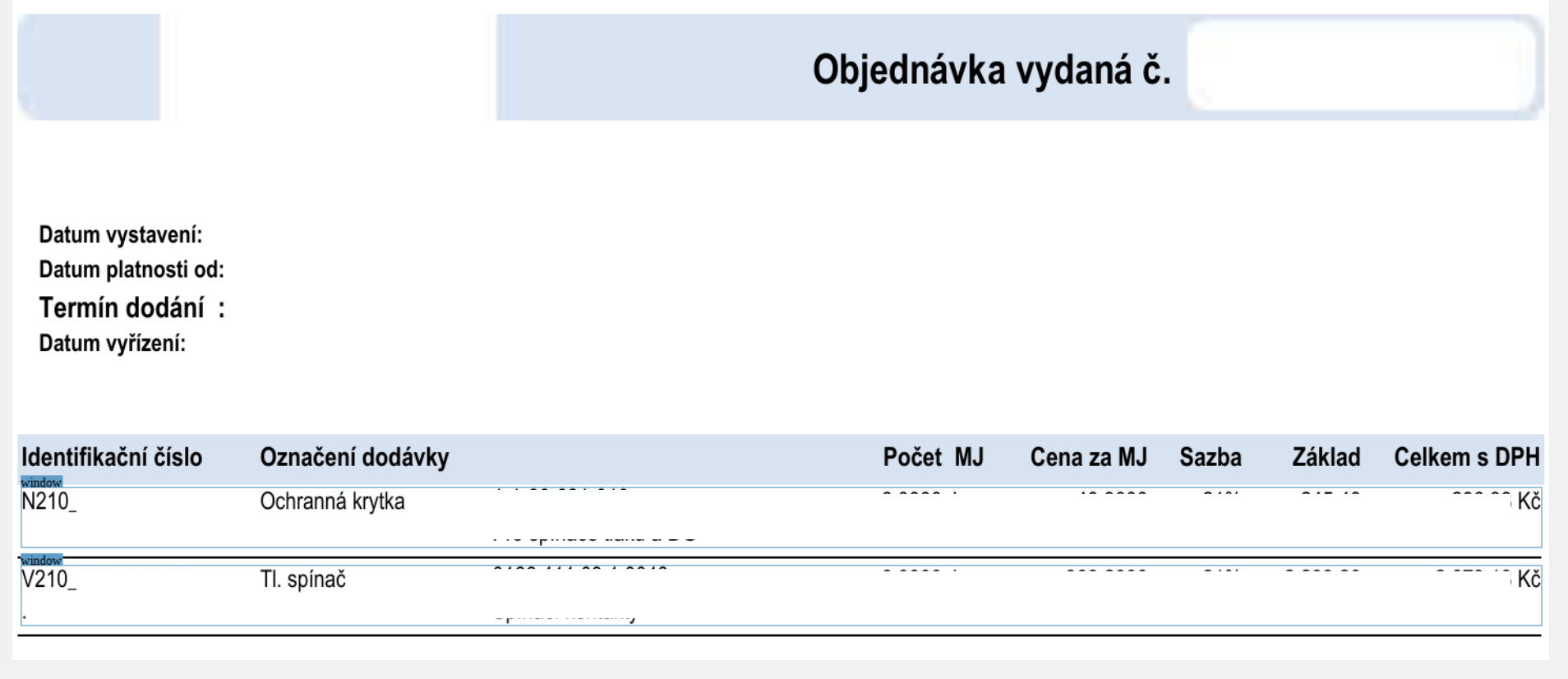
Example of document items detection
- final parse(pdf_r: PDFRobot, qr_data: QRData | None = None, csv_writer: CSVWriter | None = None) T
Main method to call to parse a provided pdf-file.
- Parameters:
pdf_r – PDF Robot with a loaded pdf-file
allow_qr_codes – If True, qr-code will be automatically detected and parsed in the pdf-file
csv_writer – Writer to automatically save parsed values
**kwargs – Any additional arguments that are passed into a
parse_body()method
- class aiviro.modules.universal_parser.UniversalParserExtension(robot: PDFRobot, qr_data: QRData | None = None, csv_writer: CSVWriter | None = None)
Extension class to inherit from for expanding or changing parsing logic of Universal Parser. Every extension needs to be specified by its context_name value.
- Example:
>>> import datetime >>> from aiviro.modules.universal_parser import UniversalParserExtension >>> # create custom parser logic for a specific item (invoice_date) >>> class MyExtension(UniversalParserExtension): ... @classmethod ... def get_context_name(cls) -> str: ... return "my-extension" ... ... def parse_invoice_date(self) -> Optional[date]: ... return datetime.date(year=2020, month=1, day=21)
- class aiviro.modules.universal_parser.DocumentType(value)
Type of documents to parse, used in Universal Parser.
- INVOICE = 'invoice'
Invoice document
- ORDER = 'order'
Order document
- class aiviro.modules.universal_parser.DocItem(rows: List[List[BoundBox]], area: BoundBox, page_index: int)
A document item is a group of text boxes that are grouped by rows together.
- Example:
>>> from aiviro.modules.universal_parser import UniversalParser >>> header, items = UniversalParser().parse_document_items() >>> for item in items: ... # access item one by one ... for r in item.rows: ... # process item by rows ... # access all boxes at once ... boxes = item.boxes
- class aiviro.modules.universal_parser.BaseSplitCondition
Base class for implementing custom split condition for the document items.
- Example:
>>> from aiviro.modules.universal_parser.item_parsing import BaseSplitCondition >>> class MySplitCondition(BaseSplitCondition): ... def should_split(self, data_row: List["BoundBox"]) -> bool: ... first_text = self._select_first_box_text(data_row) ... return first_text.text == "some text"
- class aiviro.modules.universal_parser.QRData(robot: PDFRobot)
Detects, decodes and map QR data from pdf-robot using
CzechQRInvoiceDecoder, to be accessible inUniversalParser. See section QR, Bar Codes for more info.
- class aiviro.modules.universal_parser.CSVWriter(robot: PDFRobot, file_prefix: str = 'reader_export', output_folder: Path | str | None = None)
Writer to save parsed values from Universal Parser into a csv-file. Name of the file is constructed as
{prefix}_{year}_{month}.csv.- Parameters:
robot – PDF-Robot containing parsed pdf-file
file_prefix – Prefix of the csv-file
output_folder – Folder where to save csv-files, by default log-folder from Aiviro config-file is used